On September 15, Geely’s new A-class SUV based on the CMA architecture – "Intelligent SUV Innovator" Boyue L, ushered in the first round of professional media static evaluation. At the same time, 8K ultra-high definition live broadcast sub-venues were opened in Beijing, Shanghai and other places. Thanks to China’s 5G communication technology and 8k ultra-high definition image quality, this ultra-high definition static evaluation perfectly demonstrates the beauty and workmanship of Geely Boyue L. It has a more detailed and clear visual sensory experience than the naked eye or even magnifying glass.

The novel tasting method and the exquisite texture of the Boyue L all made the "viewing" guests praise. The on-site media said one after another: "This time I didn’t come to the scene in person, but it was more real than seeing it on the spot, it was like using a microscope to see every detail of the body design and manufacturing. No matter the product or the form of the event, the’innovation ‘will be fully carried out to the end."
Under 8k, the slightest bit is visible, and the quality control of Boyue L is full of texture.
The Boyue L is the first production car based on the "Vision Starburst" concept car. It adopts the design concept of "Digital Symphony Technology Aesthetics" and is heavily integrated with the concept of technology, futurism and digitalization. With the support of 5G high-speed transmission and 8k ultra-high resolution, and a large cinema screen, the styling details of the Boyue L can be magnified hundreds of times, and the quality control of the workmanship can be more clearly displayed.

Boyue L’s light wave ripple front grille inherits the design characteristics of Geely’s classic "water drop ripple" in terms of shape, combined with new elements such as light sense, pulse, and ray, which has a strong technological taste. However, in terms of workmanship, it is necessary to vacuum quench and temper the mold material three times, polish it continuously for 25 days to achieve a mirror effect, and then spray the curved surface, mask 61 irregular discrete surfaces and 244 borders, etc., which is extremely difficult. Finally, under the precision production of Geely CMA factory’s high-precision equipment and ingenious craftsmanship, the light wave ripple front grille not only has a beautiful surface and boundary, but also uses electronic silver gray pearlescent paint to produce pearlescent effect under light, which is more three-dimensional and full visually.
Not only the front grille, Boyue L’s rich streamer light language and music light show are also more shocking and clearer on the high definition screen. The particle ray light group composed of 182 LED light-emitting units can be gradually lit or extinguished in the form of light waves in scenes such as welcome, send-off, lock car delay, etc., interpreting the deep sense of "Stargate" shape to the fullest. At the same time, the digital arrow LED through the tail light will also echo with the same visual effect. When lit, it is bright and transparent, giving users a sense of respect and ceremony while forming a high degree of recognition.

Luminous LOGO, tidal circulation waistline, 20-inch silver and black star disc wheels, etc., every detail of Boyue L shows the exquisite quality of the flagship level, which greatly enhances the user’s sensory value experience.
"Surround emotional light curtain" finishing touch, Galaxy OS Air version has smooth interaction
Take out the NFC card key and swipe it on the B pillar to unlock the Boyue L. After powering on the Boyue L cockpit, the most eye-catching is the world’s first "Surround Emotional Light Curtain", with 27 ambient light sets and LCD meters using an integrated design. During the live broadcast, the guests in the car experienced 8 major scenes such as door opening warning, music playback, nap mode, and voice interaction with the surround emotional light curtain. The 72-color tone ambient light showed a unique emotional interaction rhythm by simulating voiceprint, breathing, and water changes.

This live broadcast also conducted the first test of the Galaxy OS Air version of the car system launched by Boyue L. With the support of high-performance software and hardware such as Qualcomm Snapdragon 8155 chip, Flexray vehicle network and 13.2-inch central control vertical screen, the Galaxy OS Air version can be started and run in "seconds". What is even more surprising is that for the experience guests, "Open the car window – open the sunroof – fold the rearview mirror – reduce the temperature of the air conditioner – increase the air volume of the air conditioner – what is the weather like today – how is the stock market performing – play Jay Chou’s" Seven Lixiang "- open the seat heating – navigate to Tiananmen" and a series of complex instructions, the Boyue L car can be completed in only 25s, and the accurate voice recognition rate and execution rate are far beyond everyone’s expectations.

In terms of hearing, Boyue L is equipped with HARMAN Infinity’s Hi · Fi-class 11-sound unit sound system. In particular, the unique immersive headrest sound of the same class can realize the transmission of driving and entertainment signals, with independent sound source control, and has three modes of private, driving and sharing. The medical examination guests said that it effectively solves the pain point of interrupting music when navigating other models. When the co-pilot is riding, the system can automatically identify and intelligently switch to the driving mode according to gravity sensing. At this time, the navigation voice will be broadcast by the headrest sound, and the music will be played by other sound, so that navigation and entertainment will not interfere with each other, and create a personalized and private space for the main driver. When the co-pilot and rear passengers need to rest, they can switch to private mode, and only the headrest stereo can be heard in the whole car.

In addition, Boyue L is equipped with a double-color scheme super-sense racing antibacterial steering wheel, crystal diamond stopper, light and shadow sunglasses visor, HARMAN INFINITY luxury audio, immersive headrest audio, Air-sofa super-sense seat with adjustable leg support function and 8 major comfort functions, double-layer adjustable luggage, etc., convenient and comfortable humanized riding experience, but also left a deep impression on the reviewers.
Raytheon Hybrid + NOA empowers Boyue L’s intelligent driving experience
Due to the static evaluation this time, Boyue L’s intelligent driving and driving experience did not receive much experience, but it is still worth everyone’s expectation.
According to reports, Boyue L will be equipped with two sets of fuel powertrains, Drive-E series 2.0TD + 7DCT and 1.5TD + 7DCT. Among them, the 2.0TD engine can output a maximum power of 160kW and a maximum torque of 325N · m; the 1.5TD engine can output a maximum power of 133kW and a maximum torque of 290N · m. In addition, Boyue L will also launch a Raytheon Hi · F oil-electric hybrid version. The NEDC fuel consumption is only 4.2L/100km, and the NEDC comprehensive battery life can reach 1300km. There is no need to charge, and there is no mileage anxiety. It allows users to travel far in the city. Fully meet the diverse needs of different markets and different users.
At the same time, Boyue L will be equipped with GEEA 2.0 evolvable intelligent electronic and electrical architecture to achieve global FOTA in all scenarios and all vehicle cycles. Coupled with Boyue L’s first NOA lane-level autonomous driving pilot system, 25.6-inch giant screen AR-HUD head-up display system and Geely’s original "seven-layer intelligent safety identification circle", it will bring users a smarter, more energy-efficient and more performance driving experience.
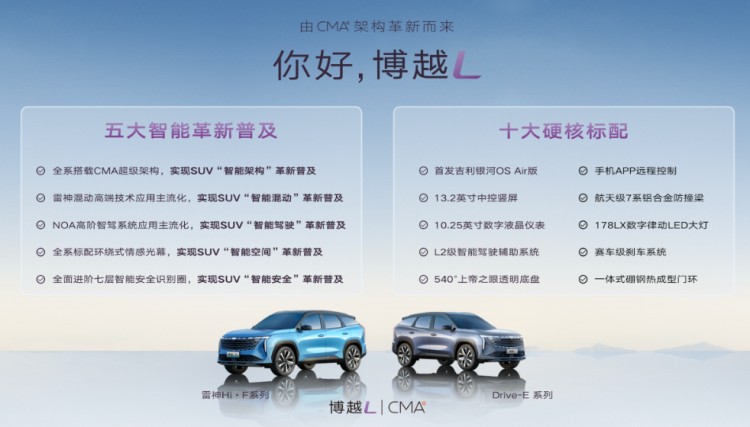
It is worth mentioning that Boyue L is still an "entry-level high-end" product, and the whole series has "ten hardcore standard": Geely Galaxy OS Air version, 13.2-inch central control vertical screen, 10.25-inch digital LCD instrument, L2-level intelligent driving assistance system, 540 ° God’s Eye transparent chassis, mobile phone App remote control, aerospace-grade 7-series aluminum alloy collision beam, 178LX digital rhythm LED headlights, racing-grade braking system and integrated boron steel thermoformed door knocker.
Such a "smart SUV innovator" with outstanding visual effects and full of details has undoubtedly raised the standard of "smart SUV". With the opening of the Boyue L tasting activities in major cities across the country and the opening of store reservations, more and more consumers have joined the "fan group" of Boyue L, and more and more fans have become prospective users of Boyue L. The popular sales scene after its listing can be predicted.